An Introduction to Machine Learning

Just a couple of decades ago, the notion of
programming machines to perform complex, human-like tasks seemed as distant as
the galaxies depicted in science fiction. Today, however, the field of machine
learning stands out as one of the most captivating industries to be involved
in. With its rapid pace of innovation and profound cultural impact, machine
learning demands resilience and courage. It rewards curiosity, celebrates
boldness, and relies on the creativity of its practitioners. If you're drawn to
these qualities of the industry, you're likely passionate about its potential.
What is Machine Learning?
Machine learning (ML) is a branch of artificial
intelligence where computers are enabled to learn from data and make decisions
or predictions without being explicitly programmed. In essence, it encompasses
techniques that empower computers to analyze data, identify patterns, and
enhance their performance over time. This capability allows machines to handle
intricate tasks previously exclusive to human intelligence, such as image
recognition, language translation, and even autonomous driving.
The Significance of Machine Learning in Today’s
World
Machine learning (ML) holds immense importance
in today’s technology landscape, profoundly influencing various industries such
as healthcare, finance, entertainment, and transportation. Here are several key
reasons why ML is crucial in shaping the products we use and the technologies
that power them:
Monitoring the Growth of Machine Learning Since the Last Century
1950s-1960s:
The Birth of ML
ML's origins date back to the 1950s and 1960s,
pioneered by visionaries such as Alan
Turing and Arthur Samuel. Turing
introduced the concept of a "learning machine," while Samuel
developed the first self-learning program for playing checkers, marking a
significant milestone in ML history.
1970s-1980s:
Rule-Based Systems
During this era, ML predominantly relied on
rule-based systems, notably expert systems that encoded human knowledge into
predefined rules. While effective in certain applications, these systems often
struggled with handling complex, real-world problems.
1990s: Emergence of Neural Networks
The 1990s saw a resurgence of interest in
neural networks, inspired by the human brain's structure. Researchers developed
backpropagation algorithms, enabling neural networks to learn from data and
generalize their knowledge. However, progress was limited by computational
constraints at the time.

2000s:
Big Data and Improved Algorithms
The 2000s marked a pivotal period for ML with
the advent of big data. The abundance of data enabled more robust training of
models, coupled with advancements in algorithms and computing power that made
deep learning and complex models feasible. This period laid the groundwork for
the modern resurgence of ML.
2010s:
Deep Learning Revolution
The 2010s witnessed the transformative impact
of deep learning. Deep neural networks, characterized by multiple hidden
layers, demonstrated remarkable success in tasks like image and speech
recognition. Landmark achievements such as AlexNet
and AlphaGo underscored the
potential of deep learning to solve complex problems.
2020s
and Beyond: Widening Applications
In the current decade, ML continues to expand
its influence across diverse domains such as finance, healthcare, and
autonomous vehicles. Innovations like explainable AI are addressing challenges
related to transparency and fairness, ensuring that ML systems make decisions
ethically and without bias based on attributes like race, gender, or
socioeconomic status. As ML evolves, its integration into everyday life is set
to deepen, shaping the future of technology and society.
Classification of Machine Learning
To gain a high-level understanding of machine
learning technology, we'll explore the three primary types of machine learning,
examining their real-world applications, advantages, and disadvantages.
1. Supervised Learning
Supervised learning is a fundamental approach
in machine learning where the algorithms learns from a labeled dataset. This
means each piece of input data is paired with its corresponding correct output
or target. The goal is for the algorithm to learn to map input data to the
correct output based on patterns it identifies during training.

Real-world
applications of supervised learning include:
Image
Classification: Distinguishing between objects in images,
such as determining whether an image contains a "cat" or a
"dog."
Natural
Language Processing (NLP): Performing tasks like language translation,
sentiment analysis, and powering virtual assistants.
Medical
Diagnosis: Detecting diseases from medical images like
X-rays or MRI scans, or analyzing patient data to predict health outcomes.
Email
Filtering: Automatically categorizing emails as spam or
legitimate based on their content and characteristics.
Recommendation
Systems: Personalizing recommendations for products,
movies, or music based on user preferences and behavior.
Autonomous
Vehicles: Identifying and interpreting road signs,
detecting pedestrians and other vehicles to navigate safely.
Advantages of Supervised Learning
Accurate
Predictions: Can make precise predictions once trained on
high-quality labeled data.
Wide
Range of Applications: Applicable to various tasks across different
domains.
Interpretable
Results: Generally provides clear insights into how
decisions are made.
Disadvantages of Supervised Learning
Dependence
on Labeled Data: Requires a large amount of accurately labeled
data for training, which can be costly and time-consuming to obtain.
Limited
to Known Labels: Unable to predict new categories that weren’t
present in the training data.
Overfitting:
Risk of memorizing noise or irrelevant details in the training data, which
reduces generalization to new data.
Supervised learning forms the backbone of many
machine learning applications and continues to drive advancements in technology
across industries.
2. Unsupervised Learning
Unsupervised learning is a branch of machine
learning that deals with unlabeled data, meaning it lacks specific target
outputs. Instead, the algorithm aims to uncover hidden patterns or structures
within the data itself.

Real-world examples of unsupervised learning
include:
Clustering:
Grouping similar data points together based on their inherent characteristics.
For example, clustering customers based on purchasing behavior to identify
market segments.
Dimensionality
Reduction: Reducing the number of variables in a dataset
while retaining important information. Techniques like Principal Component
Analysis (PCA) are used to simplify data for easier visualization or faster
processing.
Customer
Segmentation: Identifying distinct groups of customers with
similar behaviors or preferences. This helps businesses tailor marketing
strategies or services to different segments more effectively.
Anomaly
Detection: Identifying unusual patterns in data that do
not conform to expected behavior. For instance, detecting fraudulent
transactions in financial transactions based on deviations from normal spending
patterns.
Topic
Modeling: Uncovering latent topics or themes within a
collection of documents. Algorithms like Latent Dirichlet Allocation (LDA) can
identify topics based on the words and phrases that frequently co-occur across
documents.
Advantages of Unsupervised Learning
No
Labeled Data Required: Can work with raw, unlabeled data, making it
more adaptable to new and diverse datasets.
Discovery
of Hidden Patterns: Able to reveal novel insights and structures
in data that may not be apparent through manual inspection.
Scalability:
Often scalable to large datasets and can handle complex, high-dimensional data.
Disadvantages of Unsupervised Learning
Difficulty
in Evaluation: Since there are no predefined outputs,
evaluating the performance of unsupervised learning algorithms can be
challenging.
Subjectivity
in Interpretation: Results may require human interpretation to
make sense of the discovered patterns or clusters.
Quality
of Results: Results heavily depend on the quality of the
data and the algorithm's ability to extract meaningful patterns.
Unsupervised learning plays a crucial role in
exploring and understanding data in scenarios where labeled data is scarce or
unavailable, offering valuable insights into complex datasets.
3. Reinforcement Learning
Reinforcement learning (RL) is a branch of
machine learning where an algorithm interacts with an environment, learning to
make a sequence of decisions in order to maximize a cumulative reward signal.
Unlike supervised learning, RL does not rely on labeled data but instead learns
through trial and error, receiving feedback in the form of rewards or penalties
for its actions.
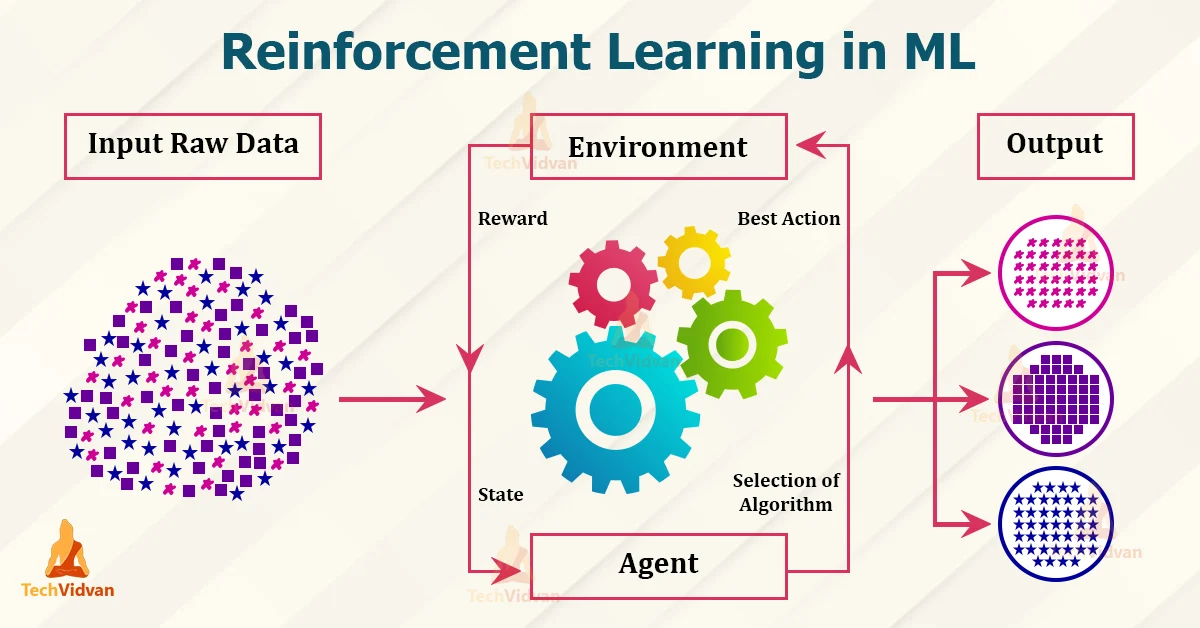
Real-world applications of reinforcement learning include:
Advantages of Reinforcement Learning
Adaptability:
Capable of learning complex behaviors and strategies through interaction with
the environment.
Real-time
Decision Making: Well-suited for applications requiring quick
decision-making and adaptation to changing conditions.
Exploration
of New Strategies: Can explore and discover novel solutions that
may not have been pre-programmed.
Disadvantages of Reinforcement Learning
Training
Complexity: Requires significant computational resources
and time for training, particularly for complex tasks and environments.
Reward
Design: Designing effective reward functions that
accurately reflect the desired outcomes can be challenging.
Ethical
Considerations: Concerns about the ethical implications of RL
decisions, particularly in safety-critical applications like autonomous
vehicles and healthcare.
Reinforcement learning continues to advance in
diverse fields, driving innovations in autonomous systems, personalized
services, and adaptive decision-making processes.
Difference between traditional programming
and ML
Machine learning and traditional programming
are distinct approaches to solving problems in computer science and software
development. Here’s a comparison of their key differences and when each
approach is typically used:
Traditional Programming
Rule-Based:
Developers write explicit rules and instructions for the computer to follow
based on their understanding of the problem domain.
Deterministic:
Produces deterministic outputs; given the same input, traditional programs will
always produce the same output.
Limited
Adaptability: Programs are rigid and require manual
modification to adapt to new data patterns or unforeseen circumstances.
Frameworks for Use
Clear
Logic: Use traditional programming where rules and
outcomes are clear and well-defined.
Structured
Problems: Ideal for situations where the problem and
its solutions are well understood.
Machine Learning
Data-Driven:
Algorithms learn from data rather than being explicitly programmed. They
discover patterns and relationships within the data.
Probabilistic:
Makes predictions based on probabilities, meaning the same input may yield
different outputs due to inherent uncertainty in the models.
Adaptive:
Models can adapt and improve their performance over time as they encounter more
data, making them suitable for dynamic and evolving scenarios.
Frameworks for Use
Complex
Patterns: Employ machine learning where patterns are
complex or difficult to specify with explicit rules.
Dynamic
Environments: Suitable for environments where data patterns
change over time or where flexibility and adaptability are crucial.
Choosing Between Them
Nature
of Problem: Consider whether the problem has clear rules
and deterministic outcomes (traditional programming) or requires discovering
patterns and adapting to new data (machine learning).
Data
Availability: Machine learning requires large amounts of
relevant data for training, while traditional programming relies on a solid
understanding of the problem domain.
Flexibility
Requirements: If the solution needs to evolve with changing
circumstances or handle complex, unpredictable patterns, machine learning might
be more suitable.
In summary, traditional programming is
effective for problems with clear rules and deterministic outcomes, while machine
learning excels in scenarios where data-driven insights and adaptive learning
are needed to tackle complex or evolving challenges. Each approach has its
strengths and is chosen based on the nature of the problem and the desired
outcomes.
Scenarios for which a Machine Learning
Model becomes a necessity
Deciding whether to use a machine learning
model or traditional programming for a project depends on several critical
factors, primarily centered around the nature of the problem and available
resources:
When a Machine Learning Model Is Needed
Processing
Complex Data: When the problem involves handling large and
intricate datasets where manual rule specification would be impractical or
ineffective. Machine learning excels at finding patterns and making predictions
in such data.
Data-Driven
Predictions: If the problem requires making predictions or
decisions based on historical data, and these patterns are not easily
discernible through traditional rule-based methods. Machine learning algorithms
can uncover hidden insights and relationships within data.
Availability
of Labeled Data: You have access to sufficient labeled data
for training and evaluating the model. Supervised learning, in particular,
relies on labeled data to learn from examples and make predictions accurately.
Adaptability
and Improvement: There's a need for the model to adapt and
improve its performance over time as it encounters new data or experiences.
Machine learning models can continuously learn and refine their predictions
based on feedback.
When a Machine Learning Model Might Not Be
Needed
Well-Understood
Problems: If the problem is well understood and a
deterministic solution can be achieved through traditional rule-based
approaches. In such cases, explicit programming can provide clear and
predictable outcomes.
Strict
Rules and Constraints: When the problem has strict, unchanging rules
and constraints that do not depend on complex data patterns. Traditional
programming can efficiently handle such scenarios without the need for learning
from data.
Limited
Data Availability: If you have limited access to data or labeled
data, making it challenging to train a machine learning model effectively.
Machine learning requires substantial amounts of relevant data for training
robust models.
Considerations
Nature
of Problem: Assess whether the problem involves
discovering patterns in data, making predictions, or adhering to deterministic
rules.
Data
Access: Evaluate the availability and quality of data
needed for training and validating a machine learning model.
Resources:
Consider computational resources, expertise in machine learning, and the
potential benefits versus costs of implementing a machine learning solution.
By carefully considering these factors, you can
determine whether a machine learning approach is suitable or if traditional
programming methods would suffice for achieving the desired outcomes in your
project.
Difference between Artificial Intelligence
& Machine Learning
AI, or Artificial Intelligence, encompasses a
wide-ranging field within computer science dedicated to developing machines or
systems capable of performing tasks that traditionally necessitate human
intelligence. This includes reasoning, problem-solving, learning, perception,
and language understanding.
Within the realm of AI, machine learning
represents a specific subset. It revolves around training algorithms to learn
from data and autonomously make predictions or decisions without explicit
programming for each task. Essentially, machine learning serves as a
methodology to realize goals within the broader scope of AI.
Therefore, while all instances of machine
learning are considered AI, it's important to note that AI encompasses more
than just machine learning. AI incorporates various techniques beyond machine
learning, including expert systems, natural language processing, computer
vision, and robotics. Each of these areas contributes uniquely to the
overarching goal of creating intelligent systems capable of mimicking human
cognitive functions and behaviors.
What comes before Machine Learning?
Before delving into machine learning, it's
beneficial to build a solid foundation in several key areas:
Programming:
Acquaint yourself with a programming language such as Python, which is
extensively utilized in the machine learning community due to its versatility
and robust libraries.
Mathematics:
Refresh your knowledge of essential mathematical principles, particularly
focusing on linear algebra and calculus. These concepts are fundamental for
comprehending the underlying algorithms and operations in machine learning.
Statistics:
Gain proficiency in basic statistical concepts such as mean, median, standard
deviation, and probability. A solid grasp of statistics is essential for data
analysis, model evaluation, and understanding uncertainty in machine learning
outcomes.
Data
Analysis: Develop skills in handling data effectively,
encompassing tasks like data cleaning, visualization techniques, and
exploratory data analysis (EDA). These skills are crucial for preparing data
for machine learning models, identifying patterns, and gaining insights from
data sets.
By establishing a strong foundation in programming,
mathematics, statistics, and data analysis, you'll be well-prepared to embark
on the journey of learning machine learning techniques and applying them to
real-world problems effectively.
Sources: wikipedia.com, udacity.com, dataversity.net,
altexsoft.com, geeksforgeeks.org, techvidvan.com
Compiled by: Shorya Bisht




No comments:
Post a Comment