From Falling Flat to Flying High: How AI Learns Like a Toddler (But Way Faster!) with Reinforcement Learning

Ever watched a baby learn to walk? It’s a messy, hilarious, and ultimately triumphant process. They teeter, they totter, they fall, they cry, and then… they get back up. Each fall is a lesson, each successful wobbly step a tiny victory. Slowly but surely, their little brains figure out the complex physics of balance, movement, and forward momentum.
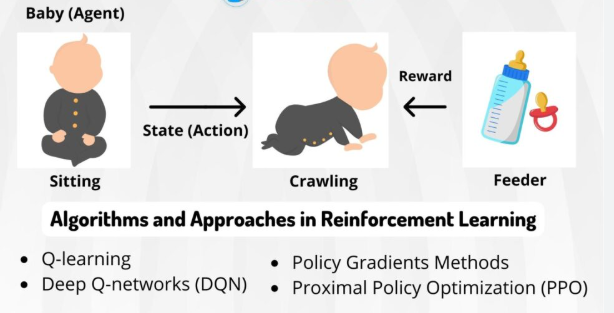
Now, imagine an Artificial Intelligence trying to do something similar. Not just walking, but playing a super-complex video game, driving a car, or even managing a vast data center’s energy use. How do you teach a machine to do something so nuanced, something that requires adapting to unpredictable situations and making long-term strategic decisions?
The answer, my friends, often lies in a fascinating field of AI called Reinforcement Learning (RL). It’s the closest AI gets to “learning by doing,” just like that determined toddler. Forget being explicitly programmed with every single rule; RL lets AI figure things out through pure, unadulterated trial and error. And let me tell you, it’s revolutionized what AI can achieve.
The Grand Idea: Learning Through Feedback
At its heart, Reinforcement Learning is elegantly simple. You have an “agent” (our AI learner) trying to achieve a goal in an “environment.” The agent takes “actions,” and the environment responds with “rewards” (good job!) or “penalties” (oops, maybe try something else!). The agent’s mission, should it choose to accept it, is to maximize its total reward over time.
Think of it like training a dog:
- You (the trainer): The Environment. You set up the world, define the rules, and give feedback.
- Your Dog (Buddy): The Agent. He’s trying to figure out what makes you happy.
- “Sit!” / “Stay!”: The Actions Buddy can take.
- Treats, Praise, Belly Rubs: The Rewards. Buddy loves these!
- “No!” / Ignoring him: The Penalties. Buddy quickly learns to avoid these.
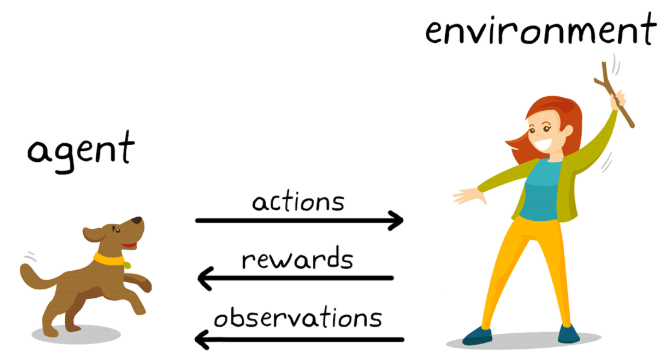
Buddy doesn’t know what “sit” means inherently. He tries different things — barking, sniffing, rolling over — and eventually, by pure chance or a gentle push from you, his bum hits the floor. Woof! Treat! Buddy’s brain makes a connection: “Sitting leads to treats! I should do that more often!” Over time, he develops a “policy” — a habit or strategy — of sitting on command.
That, in a nutshell, is Reinforcement Learning. Except, instead of treats, our AI gets numbers, and instead of a dog, it might be a supercomputer controlling a robot arm.
Peeking Under the Hood: The RL Squad
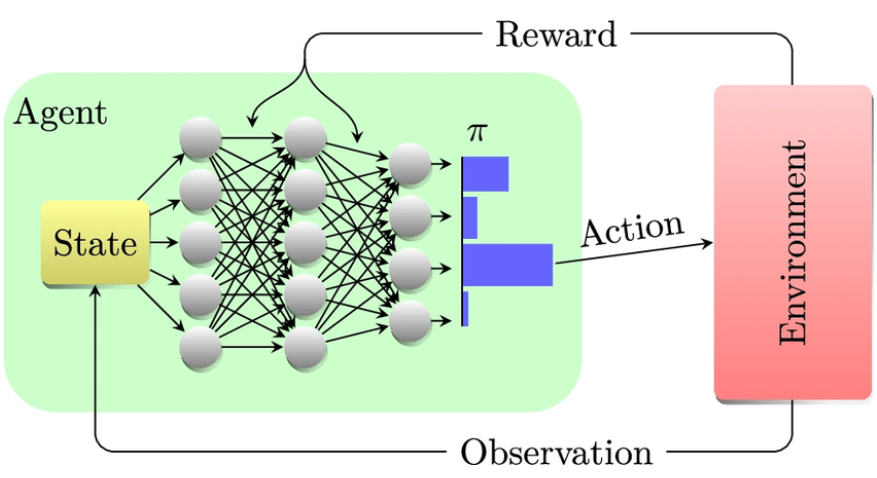
Let’s break down the key players you’ll always find in an RL setup:
- The Agent: Our Smarty Pants Learner This is the AI itself. It’s the decision-maker, the one who takes actions and learns from the consequences. It could be a piece of software playing chess, the brain of a self-driving car, or the algorithm optimizing your YouTube recommendations.
- The Environment: The World They Live In This is everything outside the agent. It’s the rules of the game, the physics of the world, the obstacles, and the objectives. For a self-driving car, the environment includes roads, other cars, traffic lights, pedestrians, and even the weather. For a robot learning to pick up a mug, it’s the table, the mug’s shape, gravity, and so on. The environment is crucial because it’s what provides the feedback.
- State: What’s Happening Right Now? At any given moment, the environment is in a specific “state.” This is simply a snapshot of the current situation. In a video game, the state might be the positions of all characters, their health, and the items they hold. For a chess AI, it’s the arrangement of all pieces on the board. The agent uses the state to decide what action to take next.
- Actions: What Can I Do? These are all the possible moves or decisions the agent can make from a given state. If our agent is a robot arm, actions might include “move gripper left,” “close gripper,” “lift,” etc. For a car, it’s “accelerate,” “brake,” “turn left,” “turn right.”
- Reward: The Pat on the Back (or Slap on the Wrist!) This is the crucial feedback loop. After every action the agent takes, the environment gives it a “reward” signal. Positive Reward: “Yes! That was a good move! Here are some points!” (e.g., scoring a goal, picking up an item, reaching a destination).Negative Reward (Penalty): “Oops! That was bad! Lose some points!” (e.g., crashing the car, losing a life, dropping the item). The agent’s ultimate goal isn’t just to get one big reward, but to maximize the total cumulative reward over a long period. This encourages strategic thinking, where a short-term penalty might be accepted for a larger long-term gain.
- Policy: My Go-To Strategy The policy is the agent’s “brain” — its strategy for deciding what action to take in any given state. Initially, the policy might be random. But through learning, the agent refines its policy to consistently choose actions that lead to the highest rewards. Think of it as a set of refined rules: “If I’m in this state, I should take that action.”
- Value Function: How Good Is This Spot? This is a bit more advanced, but super important. The value function estimates how much total future reward an agent can expect to get starting from a particular state, or by taking a particular action in a particular state. It helps the agent understand the “long-term potential” of a situation. For example, being one step away from finishing a game might have a very high value, even if the immediate reward for that one step isn’t huge.
The Learning Loop: A Dance of Exploration and Exploitation
The magic of RL happens in a continuous cycle:
- Observe: The agent looks at the current state of the environment.
- Act: Based on its current policy (and a little bit of adventurous spirit!), the agent chooses an action.
- Receive Feedback: The environment responds by changing its state and giving the agent a reward or penalty.
- Learn and Update: This is where the heavy lifting happens. The agent uses the feedback to adjust its policy. It strengthens the connections between actions that led to rewards and weakens those that led to penalties. It updates its understanding of the value of different states.
This cycle repeats countless times. And here’s where the “trial and error” really comes in:
- Exploration: Sometimes, the agent has to try new, potentially suboptimal actions just to see what happens. This is like a toddler trying to walk on their hands — it might not work, but they learn something about their body and gravity. Without exploration, an agent might get stuck doing only what it thinks is best, missing out on potentially much better strategies.
- Exploitation: Once the agent discovers actions that reliably lead to rewards, it starts to “exploit” that knowledge. This is like the toddler realizing that putting one foot in front of the other is the most efficient way to get to the cookie jar.
The tricky part is balancing these two. Too much exploration, and it never gets good at anything. Too much exploitation, and it might miss out on truly groundbreaking strategies. Algorithms like Q-learning and Policy Gradients are the mathematical engines that drive this learning and balancing act, constantly refining the agent’s policy.
Why Is This So Cool? The Power of “Learning by Doing”
The beauty of Reinforcement Learning is that it’s fundamentally different from other types of AI like supervised learning (where AI learns from vast amounts of labeled examples, like identifying cats in pictures). With RL:
- No Hand-Holding Required: You don’t need massive, pre-labeled datasets. The AI generates its own “data” by interacting with the environment. This is huge for problems where labeling data is impossible or prohibitively expensive.
- Long-Term Vision: Unlike immediate feedback, RL systems are designed to maximize rewards over the long haul. This means they can learn complex, multi-step strategies, even if some intermediate steps don’t seem immediately rewarding. Think of a chess player sacrificing a pawn to gain a strategic advantage later in the game.
- Adapts to the Unknown: RL agents can learn to handle situations they’ve never encountered before. Because they learn general strategies rather than rigid rules, they can adapt to dynamic and unpredictable environments.
Where RL is Rocking Our World
The breakthroughs in Reinforcement Learning over the past decade have been nothing short of astounding. Here are some of the most exciting applications:
Game-Playing Gods: This is where RL really captured public imagination. DeepMind’s AlphaGo famously defeated the world champion in Go, a game far more complex than chess. Later, AlphaStar conquered StarCraft II, and OpenAI Five mastered Dota 2 — both incredibly complex real-time strategy games requiring immense strategic depth, teamwork, and split-second decisions. These AIs didn’t just play well; they discovered novel strategies that even human pros hadn’t considered!

Robotics: From Clumsy to Coordinated: Teaching robots to walk, grasp delicate objects, or perform complex assembly tasks used to be incredibly difficult, often requiring precise programming for every single movement. RL is changing this. Robots can now learn these skills through trial and error in simulated environments, then transfer that knowledge to the real world. Imagine robots learning to pick fruit without bruising it, or assembling intricate electronics with superhuman precision.
Self-Driving Cars: The Future of Mobility: This is perhaps one of the most impactful applications. Training a self-driving car to navigate the chaotic complexities of real-world traffic — pedestrians, other drivers, traffic lights, road conditions — is a monumental task. RL plays a crucial role in teaching these vehicles to make safe, optimal decisions, such as when to accelerate, brake, change lanes, or react to unexpected obstacles.

Personalized Recommendations: Your Next Obsession: Ever wonder how Netflix knows exactly what show you’ll love, or how Amazon suggests that perfect product? While not purely RL, many recommendation systems leverage RL principles. They learn your preferences through your interactions (rewards for watching/buying, penalties for skipping/ignoring) and continuously refine their “policy” to suggest items that maximize your engagement.
Resource Management & Optimization: Smarter Systems: RL is fantastic at optimizing complex systems. Google, for instance, has used RL to dramatically reduce the energy consumption in its massive data centers by intelligently controlling cooling systems. Imagine using RL to optimize traffic flow in smart cities, manage energy grids, or even schedule deliveries for logistics companies. The possibilities are endless.
Drug Discovery and Healthcare: This is an emerging but incredibly promising area. RL can be used to design new molecules with desired properties, optimize treatment plans for patients, or even control medical robots during surgery.
The Road Ahead: Challenges and Ethical Considerations
While RL is incredibly powerful, it’s not a silver bullet. There are still challenges:
- Computational Cost: Training RL agents, especially for complex tasks, can require immense computational resources and time. Think of how many “falls” an AI might need in a simulation to learn to walk perfectly.
- Real-World Transfer: What an agent learns in a simulated environment might not always translate perfectly to the messy, unpredictable real world. Bridging this “sim-to-real” gap is an active area of research.
- Reward Design: Crafting the right reward function is crucial. If the rewards are poorly defined, the agent might learn unexpected (and undesirable) behaviors to game the system. This is called “reward hacking.”
- Safety and Interpretability: If an RL agent is controlling a critical system (like a car or a power plant), how do we ensure it’s safe? And if something goes wrong, how do we understand why the AI made a particular decision? These are vital ethical and practical questions.
The Human Touch in the Age of AI Learners
Reinforcement Learning is a testament to how far AI has come, mimicking one of the most fundamental aspects of human and animal intelligence: learning through interaction and feedback. It’s not about programming every single step, but about setting up the right learning environment and letting the AI discover the optimal path.
As RL continues to advance, we’ll see more and more autonomous systems that can adapt, learn, and excel in complex, dynamic environments. From making our homes smarter to revolutionizing medicine, the “trial and error” approach of Reinforcement Learning is shaping a future where AI doesn’t just process information, but actively learns to master its world, one clever decision at a time. And just like that determined toddler, it’s pretty inspiring to watch.
Sources: databasetown.com, indianai.in, mathworks.com, .researchgate.net, .reachiteasily.com, analyticsvidhya.com, bayesianquest.com, chemistry-europe.onlinelibrary.wiley.com, wikipedia.com
Authored By: Shorya Bisht




No comments:
Post a Comment